intaQt audio plugin
At QiTASC we’ve created an Audio Plugin that is currently used for monitoring speech channel quality as well as recording and comparing audio files (Audio Fingerprinting) within intaQt® test cases. Read on to find out how these new features work.

The intaQt® Audio Plugin fulfils three purposes:
- Making phone call recordings
- Monitoring a speech channel
- Detecting and comparing announcements (Audio Fingerprinting)
All of the steps and configurations described in this article are available in a dedicated intaQt® manual Audio and Speech Channel Steps and Compound Steps.
Using the intaQt® Audio Plugin requires the following setup:
- A Raspberry Pi for each phone that is used for audio recording.
- The Raspberry Pi running a service called
Audio Service. - Each Raspberry Pi is connected through a USB sound card to a given phone using a special audio cable.
- A phone’s unique mapping to the Raspberry Pi configured via intaQt® to link the phone’s serial number to the Raspberry’s IP address.

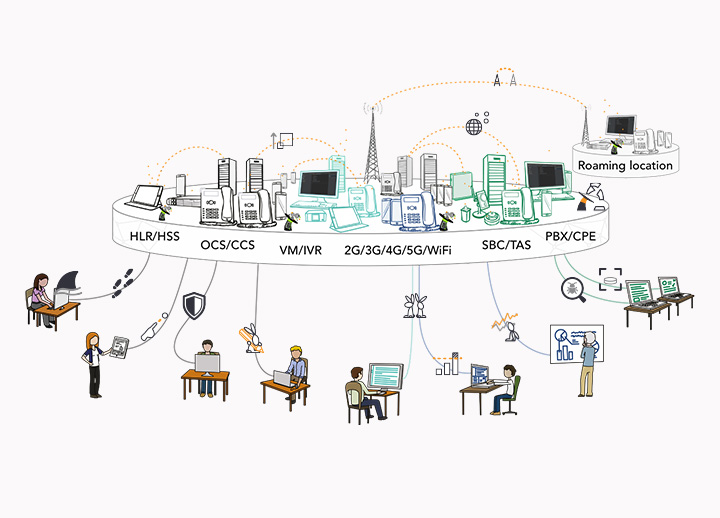
The big picture
Whenever a recording is required on a given phone, intaQt® looks up the IP address of the Raspberry Pi that it is configured to. intaQt® connects to the Audio Service on a configured URL to start, stop, and eventually retrieve the recording. The recording is a *.wav file that is attached to the test report.
The Audio Service is an HTTP (REST) service that is located on a Raspberry Pi. It permits:
- Starting a recording
- Stopping a recording
- Starting a playback of a recording
- Stopping a playback of a recording
- Retrieving a recording
- Resetting the
Audio Service
How to create recordings
A Recording Step is written in a test case, which records audio from a device. The recording is attached to the test report as a single channel (mono), 8-bit unsigned wav file with 8 kHz sample rate. This is an uncompressed, low-quality audio format that is sufficient for speech channel recordings.
Speech channel monitoring
Speech channel monitoring involves two phones (let’s call them A and B) that are under intaQt®’s control. Whenever a call is established between the phones, intaQt®’s Speech Channel Monitoring steps can be used to assess speech channel quality.
The speech channel consists of two independent directions: A => B and B => A. When a speech channel monitoring step is used, phone A plays a given reference audio file using the Audio Service. At the same time, phone B records the call established between the phones. In parallel, the speech channel’s reverse direction is covered by playing the reference audio file on B and recording it on A. The recordings on A and B are attached to the test report.
After creating the recordings, they are analyzed to judge the speech channel’s quality as described below.
How speech channel monitoring works
The reference audio files are fixed audio files that are located on the Raspberry Pi’s Audio Service. They consists of beeps with a duration of 300ms and a frequency of 800Hz and 1100Hz: One phone will play the 800Hz file and the other phone will play the 1100Hz file.
The pauses between the beeps last 300ms. Monitoring a speech channel’s quality in a given direction (for example, A => B or B => A) consists of playing back the reference file on A and recording it on B. The recording and analysis for both A => B and B => A are done once and in parallel.
When the recording on B has finished, the recorder audio file is analyzed to detect the locations and durations of beeps and pauses.

The recording’s analysis uses:
- Total number of beeps: If the total number of beeps does not meet or exceed the minimum threshold of expected beeps, the monitoring is considered failed.
- Predominant frequency: The recording’s predominant frequency must match the beeps’ nominal frequency (800 Hz or 1100Hz). If the call channel is broken, a white noise recording would fail the frequency check.
- Pause position and duration: If a pause is too long, one or more beeps are missing from the recording.
Audio fingerprinting
Audio Fingerprinting’s purpose is to match a given recording against a database of reference announcements.
Audio Matcher. The Audio Matcher reads the audio recording and uses an algorithm to compute a collection of Audio Fingerprints. This collection of fingerprints is characteristic of the recording. The fingerprints of the recording to be assessed is then compared to a collection of fingerprints that is calculated from reference recordings. Every comparison yields a similarity score between 0 and 100. A higher number indicates a stronger similarity to the reference recording.
Note:
Audio fingerprints can be visualized as a cloud of points in a spectrogram. This point cloud is characteristic of the audio signal.
Using the audio fingerprinting
Audio Fingerprinting Stepdefs are used to match reference files against recordings. The intaQt® log then shows the scores for matching the given recording with the reference database.
intaQt® matches a recording against a set of recordings announcements by:
- Calculating the recording’s fingerprints.
- Comparing the recording’s fingerprints with all reference announcements’ fingerprints. Every comparison yields a similarity score.
- The best match is the match with the highest number of equal fingerprints.
When intaQt® starts, all the *.wav files in the referenceDirectory are fingerprinted to build up a reference database. This is done for each profile and the reference database file name contains the profile identifier. intaQt® detects changes in the reference *.wav files such that those changes are properly propagated to the reference database without re-indexing all the files.

If, for the best match, the number of equal fingerprints is below a configured minimum confidence level, the match is considered to be failed. The integer number of equal fingerprints is then converted to a percentage based on the total number of the recording’s fingerprints. If this percentage is lower than the minimum score as given by the step, the match is a low-quality match.
The the match is only considered good if the similarity percentage is above the limit set by the Stepdef.

Conclusio
The intaQt® Audio Plugin expands the scope of testing by adding speech channel monitoring and the Audio Fingerprinting to its suite of features. The setup involves minimal hardware: A phone only needs a Raspberry Pi connected through a USB sound card to use these features. Both speech channel monitoring and Audio Fingerprinting provide scores to help determine if the audio quality or content matches your test’s requirements.
