What’s new in automated audio analysis? A comparison in end-to-end testing
Is a test truly and fully automated when it requires manually checking audio content, quality or conversion to text following its execution? Audio-related tasks have traditionally been excluded from software and telecommunications testing because of the complexity of integrating them into test modules. In the last couple of years, these technical and practical barriers have started to disappear, expanding the scope of what can be automated within an end-to-end test.

Is a test truly and fully automated when it requires manually checking audio content, quality or conversion to text following its execution? Audio-related tasks have traditionally been excluded from software and telecommunications testing because of the complexity of integrating them into test modules. In the last couple of years, these technical and practical barriers have started to disappear, expanding the scope of what can be automated within an end-to-end test. In this article, we’ll cover three key types of audio testing:
- Audio Fingerprinting
- Speech Channel Monitoring
- Speech-To-Text Verification
We’ll cover different use cases for each, although it’s important to mention that in many cases, a combination of these types of testing can be used. For example, when verifying audio announcements, Audio Fingerprinting and Speech-to-Text may be used: The first checks that the speaker is correct, for example, ensuring that the voice is male or female, speaks the correct language and states the proper voice prompt. The speech-to-text part further verifies that the exact text is spoken, which is especially important for dynamic parts like Dear Customer, your balance is 6.05 EUR.
Audio Fingerprinting Replaces Manually Checking Audio Files
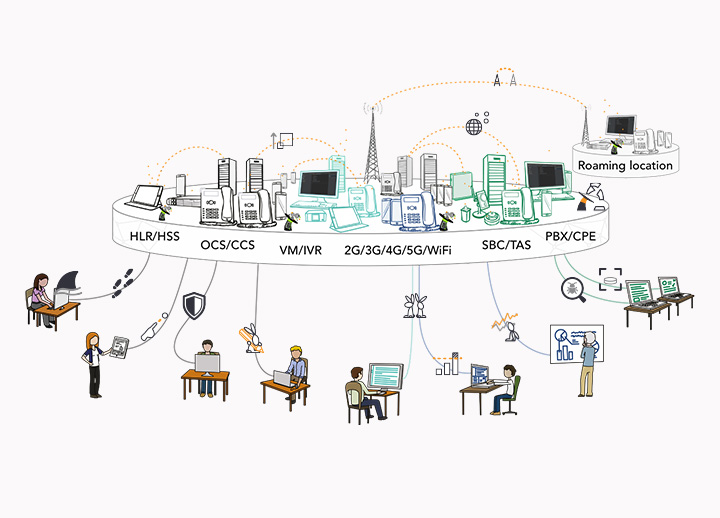
When testing telecommunications networks, one of the most challenging use cases is making sure that a customer hears the correct audio under the following circumstances:
- Navigating IVR and self-service systems
- Listening to audio announcements
- Receiving network operator messages
Test cases that include audio attachments often require users to manually replay the recordings and check that the correct file was played. These manual efforts are time consuming and can greatly decrease the benefits of an otherwise automated test case.
A typical example would be where a customer on a pay-as-you-go plan tries to make a call, but their balance is too low: An announcement notifies them that they need to “top up”. Depending on the specifications, testing the announcement may also include making sure the correct foreign language is used or that a sequence of announcements are used if the customer should be hearing multiple announcements.
To solve this productivity issue, Audio Fingerprinting automatically compares the audio generated in a test case against a set of reference files and based on the files’ “fingerprints” can determine if the correct audio was played. This is especially useful when testing long announcements and when announcements in foreign languages need to be checked.
The Problem with Testing Audio Announcements
Although call flows can usually be automated within end-to-end tests — in other words, all the activities that take place during a phone call — confirming that the correct audio announcement is played has been a pain point for productivity, efficiency and reliability. Many automation frameworks provide options to start/stop audio recordings during tests, but the user would still need to access an audio attachment and listen to it afterwards and compare it to a list of all possible announcements.
Manually checking announcements information comes with a variety of problems that reduce productivity, including:
- Replaying the announcement and comparing it with the text
- Cross-referencing the codes and numbers associated with the announcement
- Language challenges if the user isn’t fluent in the language
- Poor audio quality, requiring the test case to be re-run — often even if the correct announcement is played because it’s too hard to hear and confirm with certainty
Audio Fingerprinting to the Rescue!
The testing challenges associated with manually testing audio recordings that we described above is where where Audio Fingerprinting becomes so crucial. These fingerprints automate the test process by comparing the “fingerprint” of what was played against a reference file. The fingerprints themselves are actually spectrograms that create unique identifiers for every audio file.
While verifying audio announcements and IVR voice menus are the best-known use cases, Audio Fingerprinting can be an important solution in other contexts such as audio streaming services, sound effects and anywhere that involves confirming audio content quickly and accurately.

Confirm audio quality without listening to phone calls
Like Audio Fingerprinting, checking the sound quality of a mobile phone call has traditionally fallen outside the scope of automated testing. Manually judging audio quality is error prone because of the variety of factors that influence what a tester might hear and how they judge “acceptable” audio quality.
Speech Channel Monitoring checks for predominant frequency, pauses and distortion. This type of testing is done by automatically playing audio reference files during the call, which represents sounds that might be transmitted between two phones during a call. The content and quality of these files are then compared against a set of requirements that define acceptable tolerance, pauses, frequencies, and acceptable deviations.
Speech channel monitoring as a solution
In mobile testing, Speech Channel Monitoring is used when two phones have a call established between them:
- The “caller” party plays a given reference audio file that is recorded on the callee’s side. These recordings do not need to be complex, and contain a series of “beeps”.
- In parallel, the “callee” party plays the same reference file, which is recorded on the caller’s side.
- Eventually, both caller and callee provide recordings of the reference audio file that can be analyzed to judge on the speech channel’s quality.
- The reference audio file consists of repeated sine beeps with a given duration (300 ms) and a given pause between them (300 ms) at a given frequency (800 Hz). The recording analysis progresses in several steps.
How does speech channel monitoring work?
Although using Speech Channel Monitoring tools doesn’t require a theoretical background, the following section provides a deeper look at what goes on behind the scenes. In test cases using Speech Channel Monitoring, the following are calculated and compared:
- A spectrogram of the recording is calculated to detect the most dominant frequency contribution. Only frequency contributions with an amplitude larger than the peak
frequency limitare taken into account. These main contributions are located at the frequency of the reference signal (800 Hz). If not, the monitoring check fails: For example, if no beeps have been recorded at all because the speech channel remained silent and only produced noise). - From the most dominant frequency contribution, the frequency-over-time curve is calculated. This curve is the basis for detecting the beeps in the recording. A perfect recording would show a repeated rectangle signal. Real world signals show more or less distorted rectangles, with rising and falling edges of the rectangles of various slopes.
- The first derivative is calculated to detect the rising and falling edges of the rectangles. Spurious peaks in the first derivative are discarded and the remaining peaks are used to detect the beeps and the pauses between them.
- The beeps and pause durations are compared to those of the reference signal. This comparison is done using
duration tolerance. This is a number between 0 and 1 that indicates a percentage of allowed error. - The number of warnings that occur during mismatches, which refer to unexpected/undesired pauses or breaks in the audio transmission, for beeps and pauses are added to yield a total number of warnings for the comparison of recording and reference signal. If the number of warnings exceed the maximum allowable warnings, as configured by the user, the monitoring is considered failed.
Ensure smart home devices and virtual assistants understand users with speech-to-text recognition
At its most basic form, speech-to-text technology involves speech recognition and converting it to text. Unlike Audio Fingerprinting, which checks that a played audio file matches the expected file, speech-to-text testing makes sure that speech is properly converted into text. This type of testing also fills in gaps that Audio Fingerprinting cannot necessarily cover: Speech-to-text testing is highly suited for verifying dynamics audio, such as a customer’s name, balance or any other content that varies from the default or base audio content of a file.
Speech-to-text and speech recognition automation is most commonly associated with audio transcription tools, such as those used to transcribe interviews. However, as smart home devices and virtual assistants like Amazon’s Alexa become more common, it’s becoming increasingly important to test that the software properly recognizes voice prompts. Other areas where speech-to-text recognition’s presence is growing includes:
- Self-service menus
- Fraud detection services
- Closed captioning services
- Customer complaint analysis
- Banking and retail services

Multiple factors pose challenges to speech-to-text, such as:
- Background noise
- The speaker’s characteristics, including accent, language, how fast they speak and even their age or gender
- Microphone quality
- Esoteric and unfamiliar terms or names that devices can’t recognize
As the user base for speech-to-text tools expands and their use cases become more sophisticated, specific and diverse, the complexity of testing these tools and the need for their accuracy also increases.
Contemporary speech-to-text testing usually involves importing an audio file within the test case and automatically verifying the text output, which may also include printing it to a log for an additional quality check. Some tools integrate the Google Cloud Platform Speech-to-Text API into their automated testing frameworks, which uses machine learning to refine the validity of its speech recognition. Google’s Speech-to-Text API is especially useful for testing products with international customers, as it recognizes 120 different languages, including regional dialects.

Conclusio
In this article we covered three types of automated testing used to confirm audio content and quality: Audio Fingerprinting, Speech Channel Monitoring and Speech-to-Text recognition. With Audio Fingerprinting, the audio is automatically checked against a spectrogram to check for a match. This eliminates the need for time-consuming activities like listening and comparing files to a database, such as IVR prompts or audio announcements. Speech channel monitoring, on the other hand, confirms the audio quality of a phone call, which is difficult to determine subjectively by a human. Finally, speech-to-text recognition confirms that audio is converted to text properly, such as when using virtual devices.
